
By Dan Ryder, Jamie Roderick and Simon Robinson | LRQA Nettitude SOC
In an ideal world, every cybersecurity alert received in a SOC would be malicious; displayed with context and enriched so that it would be immediately obvious to an analyst what has occurred, and there would be automation and task orchestration to deal with the threat and self-heal the network. But then, in an ideal world, there probably wouldn’t be any SOC alerts because the security posture of an organisation would make it invulnerable to attack or compromise, and there would be no malicious actors either.
In the following post, we’ll take a look at the absolutely key processes to review, update and assure SOC cyber threat detection, reduce false positives and improve your SOC's capabilities on a continuous basis.
This is delivered by our team of SOC Monitor experts, with over 30 years combined experience across Enterprise Network Security, protecting Critical National Infrastructure and industry leading security monitoring for financial FTSE 250 companies. We'll cover the important questions you need to ask yourself in ensuring your team keep up with Threat Actors, enable your teams situational awareness and empower your SOC across the following areas:
Contents
- The problem with traditional SIEMS/SOCS
- Key Considerations
- Log Source standard patterns (do you know what is security centric versus naff on each type of device you add in? This will help remove menial logs and reduce costs)
- Performance Metrics
- Volume metrics
- Automation
- Machine Learning/Behavioural Detections
- Periodic Manual Reviews / Whitelisting process
- Proactive measures like threat hunting vs reactive alone
- Mapping to a detection’s framework
- Use cases developed early as possible
- What does good look like?
- Threat Hunting
- Automation menial low fidelity/audit/compliance alarms
- SOC Alerting pyramid of pain
- Supplemental Tools
- Visit our website to explore our SOC 24x7 Monitored Services.
The Problem with SOC Alerting
The reality (unfortunately) is very different. Malicious actors continue to evolve the sophistication and pace of their attacks, whilst security teams do their best to detect, respond and recover from attacks.
Security monitoring capabilities continue to develop and the idea of an organisation having a team with a security function (whether internal or outsourced) is well established.
However, security teams regularly struggle to deal with high volumes of low fidelity alerts. This is an issue that cannot just be solved by shiny tin - an expensive system, badly configured or un-tuned can generate so many false positives as to overwhelm a SOC and obscure actual malicious behaviour. There is only so long an analyst can spend investigating alert noise and false positives before they go log blind. A SANS survey on Common and Best Practice for Security Operations centres found that 50% of companies felt one of the main barriers to excellence is effective automation. Now, automation is not necessarily a panacea - automating bad alarms will generate activity but with little positive impact. We could employ more people - but there are practical and financial limitations to just throwing more people at the alarms.
What does good like?- Improving Security Posture, Alerting Fidelity and Cyber Capabilities
The aim, therefore, is to achieve a balance that provides high fidelity alerting to an appropriately scaled and resourced team to enable rapid detection, investigation and remediation. Simple, right? There are no silver bullets to dealing with this - the key is gain understanding - your environment, the threat, your vulnerabilities, your use cases and outcomes you want, your data, your team. Once you understand all of this, you can start to improve your alerting fidelity and detections.
Here are some key considerations and questions:
SOC Alerts Technology:
1. First, you need to make sure you are logging the full breadth of devices in your network.
Each of these gives you a different part of the puzzle:
a. Do you log Firewalls, IDS/IPS?
b. Do you log Sysmon or have a dedicated solution for good Endpoint logging?
c. Do you monitor Critical Assets, or better - Do you know what your critical assets are? E.g Domain Controllers, Perimeter Firewalls, SQL Databases et al – this is part of business intelligence and should be done before you onboard your first device.
d. Do you have Endpoint Protection & Threat Prevention, can it identify and report memory attacks?
e. Do you log NetFlow and suspicious packets? E.g Moloch/Arkime
f. Do you have Deception technology reporting into the SIEM? E.g. Honeypots
g. Does your audit policy on endpoints cover scripting?
2. Define a standard log pattern based on the type of device it is you are monitoring.
Not all logs are equal in Cybersecurity. At Nettitude, we have a number of these that cut out logs we don’t need to send to the SIEM, prioritising security-centric logs and (of course) reducing costs in storage, log rate and bandwidth
3. Now we’ve got the full gamut of devices, and they’re all sending useful logs.
What cyber threat detection frameworks are you using for your alarms? Do you have the right rules in place to detect all potential avenues of attack? E.g. Mitre ATT&CK, NIST, Cyber Kill Chain
a. Do you know what key use cases you need based on your attack surface and risk profile? Have you previously been breached and if so, how?
b. It’s important to prioritise here, such as creating alerts for the top 20 ATT&CK techniques first
c. TIP: All your alarms should have a standard scale of risk by potential impact, this could be by how high up the cyber kill chain they are, multiplied by the criticality of the device. We call these Risk-Based Priorities and regardless of what framework you use to assign risk, they’re unique to every environment.
4. Automation and Orchestration
a. What automation do you have in place – in-house or via a SOAR? Many alerts do not need an analyst to investigate, otherwise, we risk alarm fatigue.
b. How do you prioritise what to automate?
c. The following are good candidates to automatically generate incidents: Account Audit, Logon Events, Configuration Changes, File Changes, Installations and Registry changes Note: For Installations and Registry, be sure to include Threat Intelligence lookups on hashes and registry changes.
d. Be sure to have good whitelisting in place for any alarms you wish to fully automate
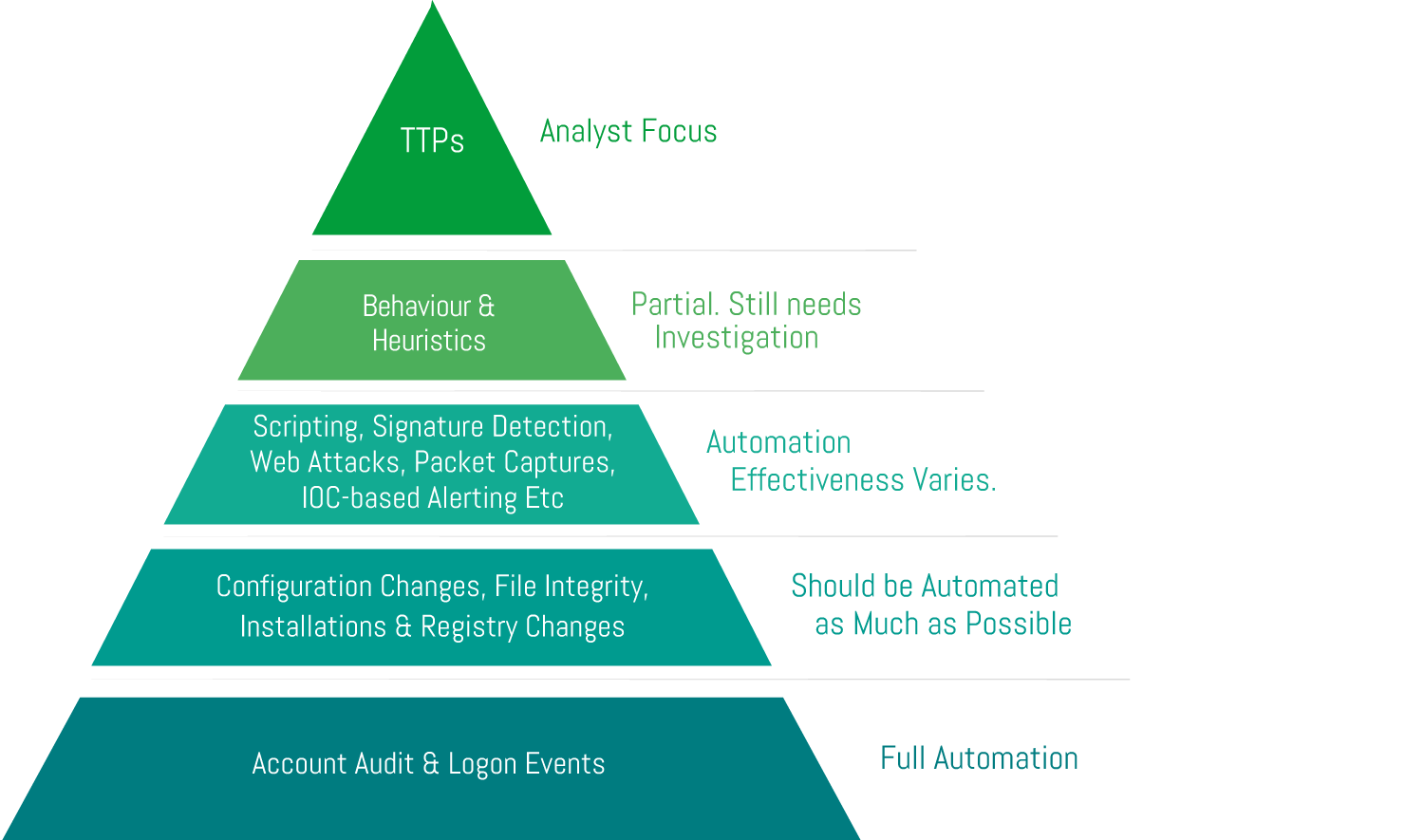
5. Performance & Volume Metrics
a. SIEMs can often act like data lakes, and these can inform some continuous improvement processes
i. E.g.: Mean Time To Respond (Whats taking the longest to investigate, or the quickest – candidates for automation?),
ii. What alerts are firing the most (these probably need tuning)
iii. How many alarms does an analyst have to manually handle daily?
iv. What percentage of alarms result in an incident? (it could indicate your priorities need work)
v. How do you handle problem management or known false-positive triggers? A very well-known example of this is Microsoft Updates utilising Base64 encoded PowerShell.
Visit our website to explore our SOC 24x7 Monitored Services.
Cyber Threat Detection Process:
Okay so you have all the right devices sending good, healthy logs into your SIEM and your Alarms are working. What next?
1. Playbooks. Work Instructions. Guides.
We can’t stress this enough, your team need to be trained in how to respond to an alert you have created. They also need to know how to differentiate between an attack and a false positive. This results in quicker response times in event of a real incident and smooths over alerting change/tuning requests.
a. Do your playbooks include flow diagrams, examples, tutorials, key investigative leads, good vs bad?
b. Do you have an incident response plan – can analysts access it?
c. Do you have an escalation matrix based on severity of an incident?
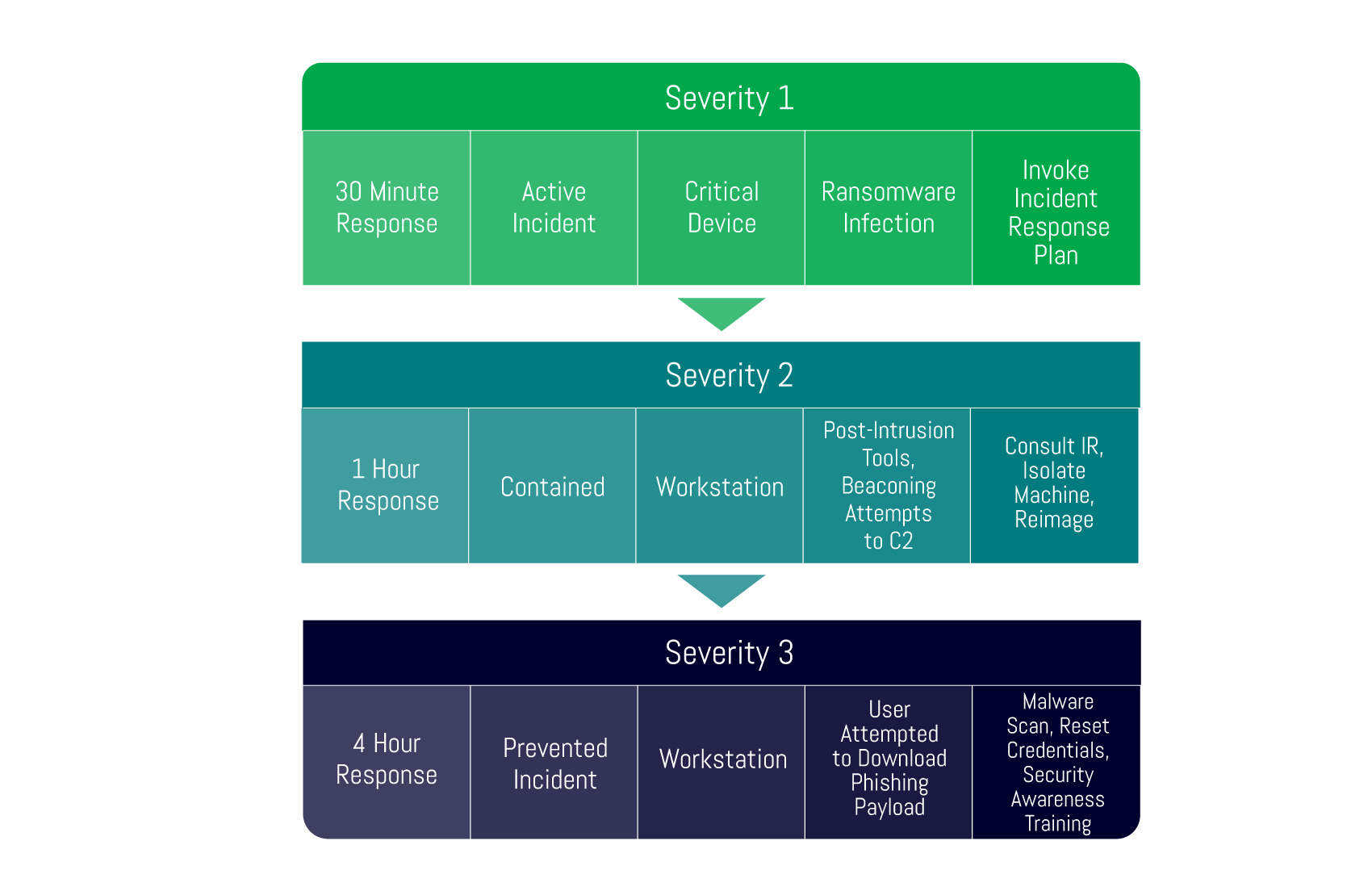
2. Severity Ratings
a. Different to risk-based priority for an alert, how do you rank a raised security incident? Is it based on impact? Activity identified? You need a sliding scale that governs what teams need to be informed as part of incident management. A ransomware infection that hasn’t been contained would not be low on the severity list
b. An example below includes hypothetical severity ratings for illustration purposes only:
3. Detections and/or Whitelisting Actions Group – How Do you Proactively Review Existing Alerting?
a. Do you have periodic meetings to review detections fidelity, bringing in Security Engineers, Developers, Technical Management and Analysts?
b. Do you have a process where analysts can submit false positives to be whitelisted as part of change management?
4. Attack Simulation
a. Do you run purple teaming events where red teamers will actively exploit weaknesses in your detections stack, then implement lessons learned?
b. Do you have a team dedicated to testing new cyber threat detections by running simulated exercises? Do you tell your analysts about these or use them as training opportunities? E.g: Dumpster Fire, Mitre Caldera, Atomic Red Team (these all feed into reducing alarm fatigue/false positives and improving alert fidelity)
5. Machine Learning and Artificial Intelligence
a. A key aspect of a SIEM, these help to aggregate alerts, events and logs together to minimise investigation times
b. User Behaviour Analytics – Do you have a known-good pattern of activity, and does your SIEM alert you when a user deviates from this a lot? E.g. Large outbound exfiltration to a new, blacklisted unknown IP
c. Endpoint Behaviour Analytics – Do your workstations have known good activity?
i. E.g. Whitelisted applications
ii. Processes
iii. Connections
6. Threat Hunting – Proactively Keeping Alerting up to Date and Plugging the Gaps
a. Virtual or dedicated Threat Hunting teams that review threat intelligence and create threat hunts across all logs, technologies and devices are critical to stay on top of new tactics, techniques and procedures that aren’t covered by your detections set
b. Findings should be analysed by a cross-functional team with lessons learned as the main outcome, be it new detections, alert tuning, process changes or revisions to the hunt
People
With process and technology, you need your people to actually drive them. You need to ensure your development opportunities and knowledge baselines are high, that way your team can identify false positives as they arise, and work with you to whitelist them. It’s a continuous process much like reducing false positives and negatives is a continuous process.
If your team aren’t trained, they’re much less likely to be able to identify whitelisting opportunities, understand alarms and follow complex playbooks.
1. Set Up an accessible wiki
Where everything is one or 2 clicks away. Better yet, build it into a single pane of glass for your analysts so a playbook is a click away from the alerting console
a. Include playbooks
b. Asset lists
c. Best practice
d. Incident Response Plans
e. Whitelisting & Change Request Procedures
2. Create a competency framework or skills matrix
Get your team to rank themselves to identify training needs, it’s a 2-way process
a. What tasks do your teams need to perform, and how do you measure how well they do it?
b. Do you enable analysts to whitelist under certain circumstances, for instance, out of hours? What permissions do they need and what competencies do they need to meet to allow that? They’re closest to the action so need to be involved in the process.
3. Internal Training, Clinic Days and Workshops
a. These should be done on introduction of new alarms & processes to get everyone on the same page
b. Even if it is a monthly town hall, allow opportunities to provide new tips, tricks and feedback
4. External Training
a. You need a training roadmap with KPIs to empower analysts to understand different attacks, analytical techniques, using different analysis tools and progress.
b. If you want to introduce threat hunting to create high-fidelity, bleeding edge alarms: what certifications and training needs to be in place for that?
None of these things are one-off activities
It is essential to ensure that the performance and efficiency of your cybersecurity alerting system are reviewed regularly and that processes are put in place to facilitate alarm tuning and whitelisting of false positives. Review your detection set and prioritise alarm development based on your threat & risk profiles. These activities are most productive when incorporated as part of the normal operational procedures within your SOC or security team.
Visit our website to explore our SOC 24x7 Monitored Services.






